4.4.1. 二叉树(I) 基础知识¶
4.4.1.1. 二叉树的概念¶
在这一部分的引论节中我们已经了解了树和森林的概况和相关的一些概念,也已经了解到了所有的树和森林类数据结构中最为重要的一种,即二叉树(binary tree),它是指所有节点都最多只有两个子节点的树。一个节点的两个子节点习惯上分别称之为左子节点(left child)和右子节点(right child)。如果将一个节点的左子节点视为根节点,从它开始的所有后代节点共同构成的子树称为这个节点的左子树(left subtree),以其右子节点为根的部分就称为它的右子树(right subtree)。
二叉树每一层上的节点数量是有规律可循的。按照树结构的定义,根所在的层为第0层,在这一层上只能有一个根节点,所以第0层有且仅有一个节点。因为一个二叉树节点最多只有2个子节点,所以每一层的节点数最多是上一层节点数的2倍。设第 \(i\) 层上的最大节点数量为 \(N_i\),则下一层上 \(N_{i+1}=2N_i\),其中 \(i=0,1,2,\cdots\),初值 \(N_0=1\)。很容易看出,这是一个等比数列,公比为2,首项为1。因此,二叉树单层最大节点数为:
由此,使用等比数列求和的方法就很容易得到一棵高度为 \(h\) 的二叉树的最大可能节点数量 \(N(h)\) 了。
根据上面的描述,我们很容易想象出一棵完美的二叉树应该有的样子,就像下面这样:
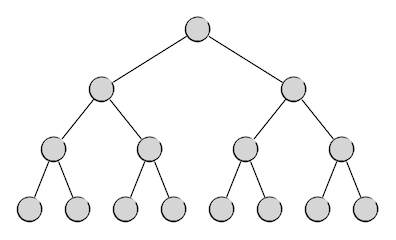
这当然是最完美的一种二叉树了,在这样的二叉树中,每一层都恰好排满了节点,我们把这样的二叉树叫做满二叉树。
满二叉树第 \(i\) 层上的节点数量一定恰好等于二叉树这一层的最大可能节点数 \(2^i\),而一棵高度为 \(h\) 的满二叉树的总节点数也一定恰好是相同高度的二叉树的最大可能节点数 \(2^h-1\)。例如上图中这棵高度为4的满二叉树,它的节点数就是1+2+4+8=15=24-1个。
显而易见,如果节点数恰好为 \(2^h-1\) 这种形式的数值,那么组织成满二叉树,高度为 \(h\),这是最低可能的高度了。所有基于二叉树操作的算法,树高越低,效率越高,因此满二叉树确实是最完美的。
但是实际应用中不可能保证节点数总是恰为 \(2^h-1\) 个的。因此我们一般就退而求其次,希望在任意的节点总数 \(n\) 下,二叉树最好能组织成下面这种样子:
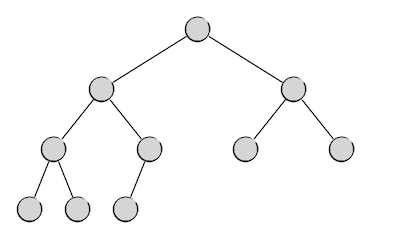
也就是说,除了最低的那一层以外,其他各层都是满二叉树的形式,而最低那一层上的节点,从左到右连续地排列,直到排完。这样的二叉树是接近完美的,我们称之为完全二叉树。于是,现在我们可以认为满二叉树是完全二叉树的一种特例。
完全二叉树是实际应用中所能追求的最接近完美的二叉树了,它也有很多优秀的性质:
若一棵完全二叉树的高度为 \(h \ge 1\),那么它的总节点数 \(n(h)\) 满足 \(2^{h-1} \le n(h) \le 2^h-1\)。
若节点总数为 \(n \ge 1\),那么完全二叉树的高度为 \(h(n)=\left\lceil \log (n+1) \right\rceil\)。
练习
用数学方法证明上面的三个性质。
现在我们可以得到这样的结论:二叉树中最为完美的组织形式为完全二叉树,为了确保数据访问效率最高,使用二叉树的算法要尽力将二叉树维持为完全二叉树或极其接近完全二叉树。
但是俗话说,世上不如意事十有八九,如果不人为地在程序中对树的形状进行监控和修整,自然生长的二叉树通常会长成各种奇怪的形状,比如:
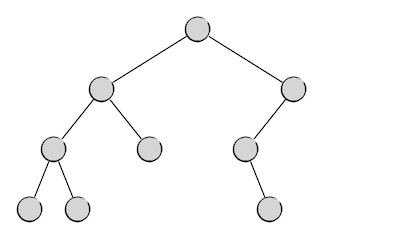
这就算是比较好的了,还有最差的情况,从树根开始总是向着一个方向延伸,于是变成这样:
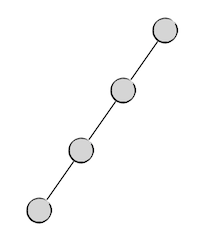
这种最差情况下,树的高度等于树中的节点数,数据访问的效率最低,实际上这是退化成了线性表。不光是二叉树,任何形式的树在应用中都要注意,绝对不能让它退化成线性表。
重要
如果保持好树的形态,使其尽可能地接近或成为完全二叉树,是所有基于二叉树的算法所需要关注的问题。要实现这一目标并不简单,比如后面要讲的二叉检索树,就需要通过不断地检查和旋转来保持身材,使之成为一棵平衡二叉检索树,否则就很容易退化,失去了二叉检索树的价值。但是检查和旋转的所谓平衡二叉树算法是比较复杂的,更加复杂的还有红黑树的平衡算法。这些技术在初学阶段可以不必掌握,但是要有所了解。
当然了,千万不要忘记只有一个树根的树也是一棵二叉树,它既是最优秀的满二叉树,又是退化成线性表的最差劲状态。
从上面这种退化状态也可以看出一个结论,一棵高度为 \(h\) 的二叉树至少有 \(h\) 个节点。所以我们可以得出通常意义下二叉树的高度和节点数之间的关系:
高度为 \(h\) 的二叉树,其节点数 \(n(h)\) 的取值范围为:\(h \le n(h) \le 2^h-1\)。
节点数为 \(n\) 的二叉树,其高度 \(h(n)\) 的取值范围为:\(\left\lceil \log(n+1) \right\rceil \le h(n) \le n\)。
给定节点数,完全二叉树的高度达到最低,退化二叉树高度达到最高。
给定高度,满二叉树的节点数达到最大,退化二叉树的节点数达到最小。
从上面的介绍我们可以看出,二叉树实际上隐含了一种递归的形式,即子树也是一棵二叉树。另外,无论从理论上还是从实践上来讲,我们都应该允许任何一种数据结构中的数据量为零,比如一张空链表,二叉树当然也不例外,当然允许有所谓的空树存在。哪怕连根节点都不存在,也应该视为一棵二叉树,即一棵节点数为0的空二叉树。于是我们就可以有下面这样的二叉树的递归定义:
二叉树的递归定义
一棵二叉树: 1. 要么没有节点,是一棵空二叉树; 2. 要么由一个根节点和它的左右两棵子树构成,且左右两棵子树都是二叉树。
4.4.1.2. 二叉树的链式结构实现¶
很遗憾,C++的STL库中没有现成的树类型的容器,所以当然也没有二叉树这种应用极为广泛的数据结构。如果遇到要使用二叉树的算法,我们只能自己编程实现一个。
二叉树最常见的实现方式为链式结构。根据二叉树的递归定义,我们只需要这样一种节点结构就可以实现二叉树了:可以存放一个数据项,有两个指向左右子树的指针,指针类型就是节点结构本身。比如下面这个简单的结构其实就已经定义了一个模板元素数据类型的二叉树节点。
#include <cstddef>
template<typename T>
struct Node {
T _value;
Node *left;
Node *right;
Node(const T &value) { _value = value; left = NULL; right = NULL; }
T &value() { return _value; }
};
这里这个简单的 Node 结构我们将在后文的示例程序中一直继续使用。它的编写方式有几个需要注意的地方:
我们将模板类型的数据项用封装惯例封装了起来,可以用
T &value()成员函数来访问数据项的引用,这样就可以实现对任何类型的数据项的高速读写访问。但是我们并没有封装左右子节点指针的成员变量
left和right,意味着程序中可以直接访问这两个成员变量,这是因为封装指针类型的变量比较复杂,如果不想使用指针的指针这种反人类的形式,那么就要将子节点的读和写分成两个不同的成员函数,就像Java中的数据域访问器一样,这是被C/C++程序员所不齿的一种做法。考虑到算法编程的特殊性,我们就不坚持数据封装了,灵活一点,直接访问成员变量就可以了。这个结构只是定义了一个二叉树的节点,并不是一棵二叉树。虽然根据二叉树的递归定义,一个节点就是一棵二叉树,只需要定义这样一个节点结构类型就足够了,但是使用的时候总觉得有点不太精准。因此一般我们在正式使用之前更习惯给它取一个听上去像二叉树的别名。另外,由于采用的是链式结构,会更多地用到节点的指针类型而非节点类型本身,所以我们通常干脆给它的指针类型定义一个别名,例如:
typedef Node<int> *BiTree;
警告
模板类型在定义别名的时候要指定具体数据类型,不能给没有具体化的模板再取别名
这样定义之后,自定义类型 BiTree 其实就是指向数据项为 int 型的二叉树节点的指针类型 Node<int> *。例如下面是一个简单的示例程序,请仔细阅读,学会怎样生成节点、添加子节点、读取和修改节点中数据项的值等最基本的操作:
#include <cstddef>
#include <cstdio>
template<typename T>
struct Node {
T _value;
Node *left;
Node *right;
Node(const T &value) { _value = value; left = NULL; right = NULL; }
T &value() { return _value; }
};
typedef Node<int> *BiTree; // 定义一个具体的二叉树节点的指针类型,数据为int型
int main()
{
// 生成根节点,值为4
BiTree root = new Node<int>(4);
printf("root = %d\n", root->value());
// 修改根节点的值
++root->value();
printf("root = %d\n", root->value());
// 添加左右子节点
BiTree left_child = new Node<int>(10);
root->left = left_child;
root->right = new Node<int>(20);
printf("left = %d, right = %d\n", root->left->value(), root->right->value());
delete root->left;
delete root->right;
delete root;
return 0;
}
小技巧
在实际使用中,为了方便访问,往往会把父子关系做成双向链的结构,即每一个节点都再增加一个指向父节点的成员变量,以便从子节点回溯到父节点去。根节点的父节点指针规定为 NULL。但是这样的双链结构会增加节点增删时的工作量,添加子节点的时候要同时维护好子节点的父节点指针才行。后面我们会很快看到这种双链结构的二叉树。
4.4.1.3. 二叉树的顺序结构实现¶
除了上面这种最常见的链式结构以外,二叉树其实也可以基于顺序表,比如最简单的数组来实现。基于顺序结构实现的二叉树,在代码形式上能够更加简洁,在节点的查找与读写上也可以利用按下标直接访问的优势提高速度。
假如我们将一棵二叉树中的所有节点按照层次从上到下、同层从左到右的顺序依次从0开始编号。根节点规定为0号节点,那么根节点的左右两个子节点就分别为1号节点和2号节点。再下一层,从左到右依次是1号节点的左右子节点和2号节点的左右子节点,它们的编号依次为3、4、5、6号。例如下面这样一棵满二叉树:
0
/ \
/ \
/ \
/ \
/ \
/ \
1 2
/ \ / \
/ \ / \
3 4 5 6
/ \ / \ / \ / \
7 8 9 10 11 12 13 14
我们可以发现,每一个位置上的节点编号和它的父节点编号是有确定的关系的。对于任意一个编号为 \(n\) 的节点:
父节点编号:\(\text{Parent}(n)=\left\lfloor\frac{n-1}{2}\right\rfloor\)。
左子节点编号:\(\text{LeftChild}(n)=2n+1\)。
右子节点编号:\(\text{RightChild}(n)=2n+2\)。
所以我们可以把一棵二叉树的节点按照这样的规则放进一个数组里去,节点的编号就是在数组中的位置下标。为了表示某个位置没有节点,我们应该使用指向数据项的指针数组而不是实际数据项的数组。例如下面这个程序,定义了一个基于数组的二叉树结构类型,并且进行了和上面这个链式结构二叉树示例程序类似的测试。
#include <cstddef>
#include <cstring>
#include <cstdio>
typedef unsigned int Node; // 用数组下标来代指节点,定义一个类型别名
// 计算父节点编号
inline Node parent(Node n) { return (n - 1) / 2; }
// 计算左子节点编号
inline Node left_child(Node n) { return n + n + 1; }
// 计算右子节点编号
inline Node right_child(Node n) { return n + n + 2; }
const int MAXN = 1023; // 1024个节点,支持最大10层的二叉树
template<typename T>
struct BiTree {
T *_nodes[MAXN];
BiTree() { memset(_nodes, 0, sizeof(_nodes)); }
~BiTree()
{
for (int i = 0; i < MAXN; ++i)
if (_nodes[i]) delete _nodes[i];
}
// 判断节点是否存在
bool has_node(Node n) const { return _nodes[n]; }
// 重载[]运算,使得可以按下标值访问节点
T &operator[](Node n) { return *_nodes[n]; }
// 插入一个新的节点
void insert(Node n, const T &value)
{
if (!_nodes[n]) {
_nodes[n] = new T;
*_nodes[n] = value;
}
}
// 删除一个节点
void erase(Node n)
{
if (_nodes[n]) {
delete _nodes[n];
_nodes[n] = NULL;
}
}
};
int main()
{
Node root = 0;
// 生成一棵二叉树,数据项为int型
BiTree<int> tree;
// 插入根节点,数据值为4
tree.insert(root, 4);
printf("root = %d\n", tree[root]);
// 修改根节点的值
++tree[0];
printf("root = %d\n", tree[root]);
// 添加左右子节点
tree.insert(left_child(root), 10);
tree.insert(right_child(root), 20);
printf("left = %d, right = %d\n", tree[left_child(root)], tree[right_child(root)]);
return 0;
}
从读写节点数据的实际运行速度来看,用顺序结构实现一定会更快一些,因为顺序结构天生就比链式结构的读写效率高。而且顺序结构的代码也更加简洁,最极端的情况是有明确取值范围的基本数据类型数据项,这种情况下甚至不需要用指针数组,任取一个不在取值范围内的值作为该位置没有节点的标识。例如非负整数的二叉树,直接用 int 数组构造即可,用值 -1 表示此处没有节点,而 -1 又恰好可以用 memset() 函数批量赋值。这种情况下顺序结构的二叉树代码会非常简洁优雅。
但是顺序结构实现二叉树有一个非常致命的问题,那就是空间浪费。试想在上面的代码中,我们用一个长度为1023的数组作为基础。按照二叉树层与节点数量的关系,这个数组支持存放最多10层的二叉树。如果遇到稀疏的树形,节点数远少于1023个,空间就被浪费了。极端情况下,10层的二叉树最少可以少到只有10个节点,1013个数组元素空间被浪费。
绝大多数算法问题会给出明确的数据量,假如我们已经知道了最多有可能有 \(N\) 个节点,而且二叉树的形状并没有特别的控制,那么我们要考虑最坏情况,可能会是 \(N\) 层,不排除每一层都是最右边的节点的情况,即上面示意图中沿着 0->2->6->14 这条边一路贴着右边界下来的情况。所以我们需要准备一个长度为 \(2^N-1\) 的底层数组,\(O(2^n)\) 级别的空间复杂度,太可怕了!算法竞赛一般要求内存使用不超过128M,那么最大可能的节点数大概为25个以内,一旦 \(N\) 超过30,普通的家用电脑就没得玩了,如果 \(N\) 等于64,那么把全世界的内存加在一起也不够了。
所以如果不控制二叉树的形状,顺序结构几乎就是没有任何实用价值的。要用顺序结构,就必须控制二叉树的形状。
重要
顺序结构实现的二叉树,一般都要求是完全二叉树,或总是非常接近完全二叉树。高级数据结构堆就是一个非常典型的例子。